James Wu
Department of Computer Science
McGill University, Montreal, Quebec
wuj@cs.mcgill.ca
More than thirty years ago, the first author was asked about the potential for the use of computers in the reconstruction of ancient manuscripts from fragments. This resulted in two publications (Levison, 1965 and 1967), while independently Ogden (1969) presented a PhD thesis describing the use of a computer to assist in piecing together one of the Chester-Beatty papyri. As far as we have been able to discover, there has been no further published work on this topic. In the case of the most famous collection of fragmented manuscripts, the Dead Sea scrolls, scholars apparently made no use of computers for their reconstruction, though this aspect of their work may have been substantially complete before computers were readily available. Wacholder and Abegg (1991) used a computer in an effort to reconstruct the unpublished Dead Sea scrolls from a concordance, but this is much simpler than the tasks described here, since the concordance already gives the location of each component.
The many-hundredfold increase in the speed and capacity of computers over the intervening period caused the authors to revisit this problem, and consider solutions which were infeasible in the 1960's.
A fragment consists of a few lines of text, each containing a few characters of some alphabet. The word "few" is purposely vague. It should be noted, however, that if a fragment contains a substantially complete non-trivial word and comes from a known text, a scholar will likely recognize it, either directly or by consulting a concordance. Contrariwise, if a fragment is sufficiently small, containing only a couple of common letters, it might be found almost anywhere in any text, and is essentially useless for reconstruction purposes. We shall return to this topic later.
As it happens, there are two different types of reconstruction problem, each involving a different strategy for its solution. Commonly, the text from which the fragments come is already familiar (say, it is a variant manuscript of the book of Isaiah), and can be recognized instantly from some of the larger fragments. In this case, the best strategy for reconstruction is to locate each fragment in an existing copy of the text. This is analogous to solving a jigsaw puzzle by laying each piece in its proper place on a full-size version of the finished picture, without reference to, or comparison with, any other piece of the puzzle. To the extent that we can achieve this, we obtain an approximation to the required result. We call this Jigsaw Problem A.
On the other hand, when the text is unfamiliar, we must resort to comparing pairs of fragments to discover juxtapositions in which, say, the right edge of one fragment is a good match for the left edge of another, and reasonable letter sequences are formed across the boundary. This is analogous to solving a jigsaw puzzle whose picture is unknown. We call this Jigsaw Problem B.
To investigate the solution of Problem A, a simple experiment was conducted using an electronic version of Lewis Carroll's Alice's Adventures in Wonderland (Duncan Research, 1991). A paragraph chosen at random by one of the authors was reformatted to a different page width and printed in a fixed font. It was then divided into fragments using horizontal and vertical lines (Figure 1). The resulting fragments were entered into the computer in a specified format, and used by the other author for reconstruction.
In this edition, Alice contains about 150,000 characters, of which the chosen paragraph has 922, divided into 53 fragments, averaging 17 to 18 characters each. (The whole text would therefore contain about 8600 fragments of similar size.)
A fragment-searching program was written by the second author. Essentially, this attempts to locate the first line of the fragment in the text, followed within a certain range by the second, and so on. Initially this range must be quite broad, since the line width and layout of the fragmented manuscript may not be known. Later, when several fragments have been successfully located, the range is refined.
Levison (1965), which was concerned with minimizing computer time to make the process feasible, describes three algorithms for the search. Since timing is no longer an issue for Problem A, the current program used the simplest of these, locating all 53 fragments in the entire text in about 12 seconds, using a Pentium Pro 180 PC.
Of the 53 fragments, 51 were sited uniquely in the text, while one was located in more than 120 positions. The remaining fragment gave rise to four sites, but these were, in essence, a single position with four alternative locations for the first line ("he "). These results accord with the analysis in the next section.
The algorithm used in the program is linear with the number of fragments (and also with the length of the text.) Thus we might expect to locate a complete set of fragments for Alice in about 30 minutes.
Let us look more closely at the results we might expect to obtain from the preceding process, given the size of fragments and the relative frequencies of their letter sequences. We will assume that these frequencies are largely independent of the content, and that particular sequences are scattered randomly through the text. Clearly, this is not true in all cases. For example, the letter sequence "Alice" occurs far more often in Alice than in English texts as whole, while occurrences of "Hatter" are confined to a fairly small section. We are, however, concerned only with orders of magnitude, rather than precise values.
Let f(x) denote the frequency per letter for the letter sequence x in the language of the fragments. Approximate values for the frequencies per letter of single letters in English are shown in Figure 2. We see that f("e") is 0.084, implying that 8.4% of letters in a typical English text are "e", or put another way, that 0.084 is the probability that a letter chosen at random in an English text will be an "e". Similar tables can be established for letter sequences of lengths 2, 3, ... (which we will call digraphs, trigraphs, ...) by tabulating occurrences in a cross-section of texts.
______
a 0.053 b 0.011 c 0.014 d 0.031 e 0.084 f 0.014 g 0.016 h 0.046 i 0.047 j 0.001 k 0.008 l 0.030 m 0.016 n 0.045 o 0.055 p 0.009 q 0.0009 r 0.041 s 0.042 t 0.064 u 0.022 v 0.006 w 0.016 x 0.0009 y 0.016 z 0.0004
Figure 2. Approximate frequencies per letter for single letters
in English. (The space character accounts for most of the missing fraction.)
______
Let f1, f2, f3, ... denote the frequencies per letter of the first, second, third, ... lines of a fragment. (If a fragment has a line of length 5, say, and we have frequency tables only up to trigraphs, the least frequent trigraph provides an upper bound and an adequate estimate.) Let V be the width of the range of letters to be scanned for a line other than the first.
Then, the probability that the first line starts at a particular letter in the text is f1; and the probability that a later line starts in any of V successive positions is given by:
(approximately V.fn if fn is very small). Then P = (f1.p2.p3 ...) estimates the probability that a given fragment arises at a particular site in the text purely by chance.
Now suppose the length of the text (in letters) is T. Then if P.T is much less than 1, this fragment is unlikely to occur in the text by chance alone. So, provided that the fragment is actually present, we can expect to find exactly one location -- the correct one. On the other hand, if P.T is much more than 1, then the fragment can be expected to occur many times by chance alone, and the reported locations will be helpful only if most of these can ruled out, perhaps by overlap with uniquely positioned fragments. Values of P.T near to 1 can be expected to yield a few locations, and overlap or shape must be used to choose between them.
This is exactly what is observed for 52 of the fragments in the experiment; and in fact, the 53rd is positioned uniquely if we ignore its first line. This first line is itself so common that it occurs several times on every line of text [1]. Hence the result.
Where the text of the fragmented manuscript is unknown, a completely different strategy is necessary. Based on a digitized representation of the shapes of the fragments as well as frequency tables for digraphs, trigraphs, etc. and perhaps a lexicon of the language, we need to develop a scoring algorithm, and apply it to all possible juxtapositions of the fragments, to find the "best" matches. In this way, we seek to build horizontal bands of text (assuming the language involves letters written horizontally across a page) from which the manuscript can be reassembled.
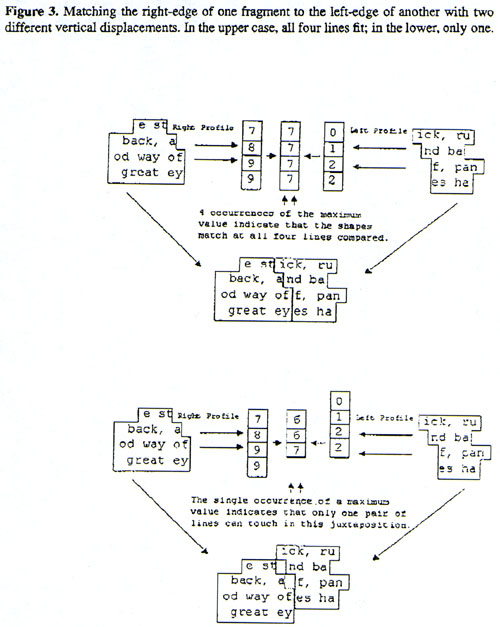
Using the previous set of fragments, we experimented with several scoring algorithms. Because of the (oversimplified) method used to create them, the left- and right-edges of these fragments can be represented by columns of integers giving the displacement of each line-end (in character widths) from an arbitrary vertical datum. The differences between corresponding integers allow us to determine which lines fit. This is illustrated in Figure 3.
These experiments had limited success. The fits identified as best for a given fragment were rarely the correct ones, though the correct fits were often among the top five. The process in its present form, therefore, reduces human comparison substantially but does not replace it. The reason is easy to discover. Whatever the scoring algorithm, shape inevitably assumes far greater importance than language information, since we cannot even use the latter on lines which do not fit together. This works against vertically displaced correct fits, which are at a disadvantage compared to "square on" incorrect ones. And, of course, the oversimplification of the shape causes far too many apparent shape matches. This problem can be overcome with a more accurate shape representation, but feasibility then becomes an issue.
In contrast to Problem A, computing time for Problem B is a significant consideration. For a set of n fragments averaging p lines each, there are roughly 2p.n2, possible juxtapositions [2]. This amounts to around 25,000 for the 53 fragments above, 700 million for the whole of Alice. (To put this into perspective, if the scoring algorithm were to take 100 microseconds, the full comparison would require 200 hours.)
The computation can be rearranged. Typically, a human might inspect a fragment to determine the possible characteristics of the one to its right, and then search for a fragment having these features. This does not reduce the number of comparisons to be made, unless these characteristics allow the fragments to be classified or sorted, so that the search can be limited to a fraction of them. Nonetheless, the characteristics of the neighbours of each fragment need be computed only once, and approximate matches might be used to limit the number of neighbours which have to be examined in more detail. We will investigate this in subsequent work.
In summary, Problem A can be solved very efficiently with a computer, provided that the fragments are not so small as to make a solution meaningless. Furthermore, there is an analysis which can be used to determine a priori whether any or all fragments can be sensibly located.
A computer solution to Problem B is more difficult, currently reducing rather than eliminating human comparison. A more complex comparison process along with faster (or parallel) processing is likely to alter the balance.
Thus, when a 40th century London shepherd strays into a cave, comes upon the archaeological remains of the former British Library, and finds the fragmented manuscript of Alice's Adventures in Wonderland, she should be able to reconstruct it quickly, using her trusty PC Laptop.
{kind=link}
{kind=link}