The University of Virginia Library is in the process of building a reference collection of visual images to support research in the humanities.[1] The means and methods of creating, managing, and distributing this kind of electronic information are still under debate in the visual resource community, where the alphabet soup that characterizes the image standards environment is thick with metadata possibilities. This presentation will focus on identifying a semantic standard and defining a syntactic model for the description of images.
Image metadata creators must make both syntactic and semantic choices to organize and describe their data; these choices reflect their understanding of the scope, function, and usage patterns of a collection and are based on underlying assumptions for scholarly inquiry in a specific discipline.[2] Metadata creators must be prepared to act as interpreters of content and context, assigning meaning within a chosen frame of reference.
The interpretive role given to creators of both the syntax and semantics of image description is supported by the very framework for presentation and analysis of visual material that has developed over centuries of art historical inquiry.[3] In traditional analysis, the language of form is re-expressed through the spoken or written word: the act of description confers meaning to the object.
Defining descriptive standards for works or art does reinforce this reliance on text-based interpretations[4]: and implies an understanding of the verbal codings of the 'subject' of a work, its "of-ness" or "about-ness."[5] Ambiguities and inconsistencies are inevitable when description depends on so many layers of individual interpretation of meaning.[6] The challenge remains to design a descriptive model that is based on standards yet is flexible enough to allow the tying together of seemingly disparate elements with the thread of a unifying idea.[7]
Image description does present considerable challenges in defining an appropriate and inclusive model. Issues of organization, hierarchy, relation, and surrogacy are critical to defining content and context and must be considered when deciding whether or how to give access to individual media objects as well as to 'natural' groupings of materials.[8]
Several different electronic encoding schemes are currently used to describe image collections, with varying degress of success,[9] and this paper will briefly review such efforts as the Categories for the Description of Works of Art <http://www.gii.getty.edu/index/cdwa.html>, the ICOM-CIDOC model, CIMI's standardization efforts <http://www.cimi.org/documents/meta_peerreview_announce.html>, the VRA Core <http://www.oberlin.edu/~art/vra/wc1.html>, and others. Important to our effort is the Dublin Core, a metadata set designed to support resource discovery in a networked environment, which has been adapted for the description of image collections in several projects <http://www.purl.org/DC/projects/subject.htm>.[10]
So, useful semantics for image description do exist. Although the Dublin Core is intended for resource discovery, the development of qualifiers to the simple 15-element set makes it a powerful and flexible metadata set for images. CIMI's Dublin Core Metadata Testbed Working Group has demonstrated the feasibility of this element set to the world of museum objects. What's missing then from the picture is the syntactic model that gives expression to these elements and to the relationships among the elements and to other information sources.
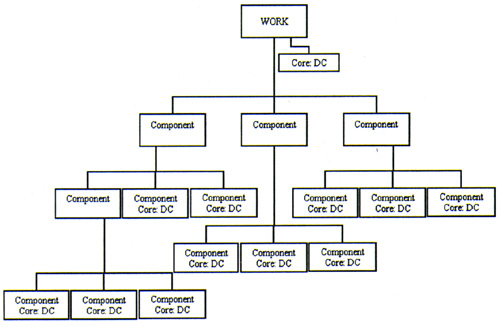
The descriptive model for images that we have developed at UVa is one building block in the digital library architecture being designed under the direction of Thornton Staples, the Director of Digital Library Research and Development. It is intended from the outset to be expressed in SGML/XML, since its multi-level hierarchy and system of inheritances would be denied complete expression in a relational database. The image description model embeds in each level of the hierarchy a full Dublin Core element set, defining each level as a "logical cluster of metadata" and thus adhering to the 1:1 principle of description in the Dublin Core (DC).[11]
At the top level of the hierarchy is a Work. This Work can be expressed as a core (DC), and, at the next level down in the hierarchy, can contain one or more components. Each component of the model must itself contain a descriptive DC core - and/or other components. Components themselves can be targets to other works, or to components or elements in the same or different work. The semantics of the Dublin Core allow for description of the agents involved in the creation or production of the work, its components, the surrogates, or even the metadata.
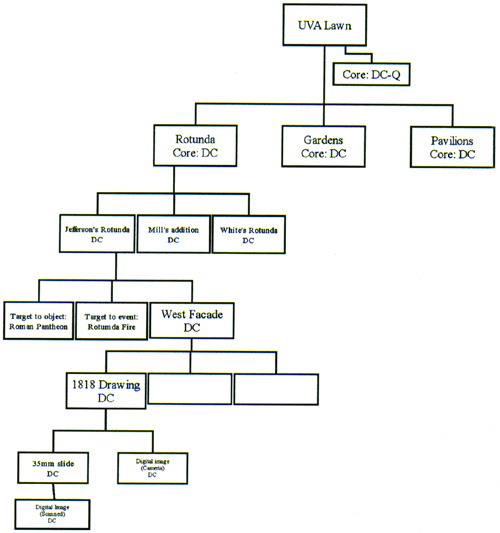
The system of inheritances is such that the values of the elements of any level of the hierarchy are carried to the levels below it unlesss they are explicitly replaced by new values.
This model solves many of the troublesome problems of image description. A building can have multiple building dates with various architects responsible for different portions; a polyptypch can be attributed to several artists and its panels distributed among different museums. Both can be adequately described according to this scheme. Best practices will include recommendations for data entry, standard vocabularies and schemes for the different elements, but the modular nature of the information structure will allow for extensibility and flexibility in terms of granularity and collection groupings, and ultimately, points of view.